What If()? Using Conditional CSS Variables

A cool new feature is coming to CSS: if().
With this, you can set a style or a CSS variable based on some condition, like whether the device is on a touchscreen, or whether some CSS property is supported, or even based on an attribute on an element.
It’s really cool, and sooner or later we’ll all be (ab)using it.
Actually, you can pretty much do this today using CSS Variables, with a little understanding of how variable fallbacks work and how you can use this to make your own conditionals.
What are CSS Variables?
CSS Variables make it easy to use reuse colors and styles across a CSS codebase. At their most basic, they look like this:
:root {
--my-fg-color: red;
--my-bg-color: blue;
}
body {
color: var(--my-fg-color);
background: var(--my-bg-color);
}CSS Variables can have fallbacks, which falls back to some other value if the variable isn’t defined. Here, the color will be black if --my-custom-fg-color wasn’t defined in the scope.
body {
color: var(--my-custom-fg-color, black);
}This can be nested with other CSS variables:
body {
color: var(--my-custom-fg-color, var(--my-fg-color, black));
}Fallbacks depend on whether the variable is truthy or falsy.
Truthy and Falsy Variables
When a variable is falsy, var() will use the fallback value.
When it is truthy, the fallback value won’t be used.
Normally, it’s falsy if the variable isn’t defined, and truthy if it is. But there are a couple tricks to know about:
- You can make a variable falsy by setting it to the special keyword
initial. - You can make a variable truthy (without expanding to a value) by making the value empty.
Let me show you what I mean:
:root {
/* Empty -- Truthy and a no-op */
--no-fallback: ;
/* 'initial' -- Falsy, use fallback */
--use-fallback: initial;
}
body {
background: var(--no-fallback, grey);
color: var(--use-fallback, blue);
}This will result in the following CSS:
body {
background: ; /* No value -- ignored. */
color: blue;
}Our new --use-fallback will ensure the fallback value will be used, and --no-fallback will ensure it’s never used (but won’t leave behind a value).
These are our core building blocks for conditional CSS Variables.
We can then combine these rules.
body {
background:
var(--no-fallback, red)
var(--use-fallback, pink);
color:
var(--no-fallback, pink)
var(--use-fallback, red);
}This will give us:
body {
background: pink;
color: red;
}Behold:

You can play around with it here:
Armed with this knowledge, we can now start setting CSS Variables based on other state, and trigger the conditions.
Setting Conditional Variables
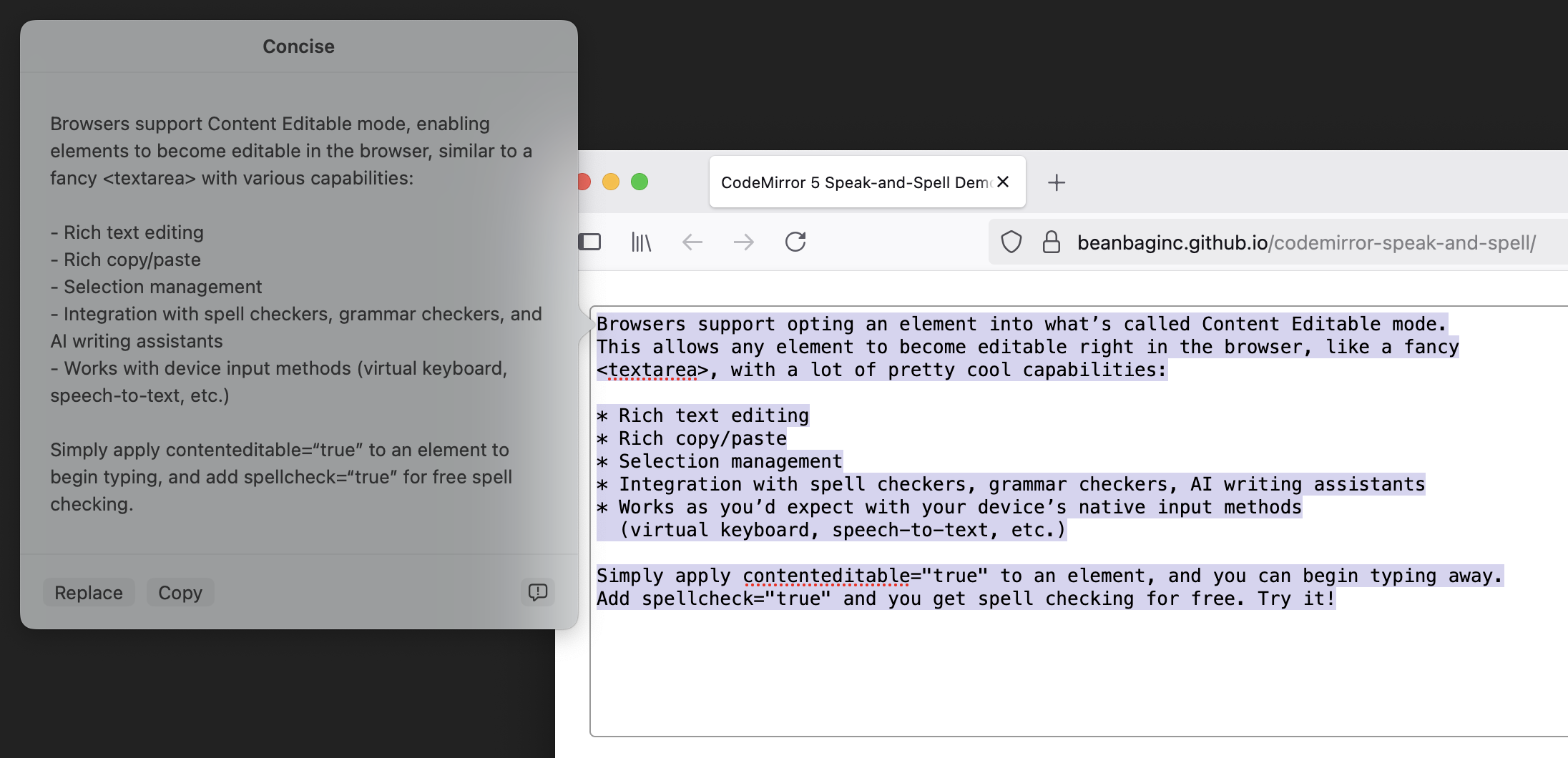
Let’s set up another contrived example. We’re going to put together some HTML with a button that styles differently based on where it’s placed. In this case, when in <main>, it will appear blue-on-pink and elsewhere it’ll appear pink-on-blue.
It’s my post and I will use hideous color palettes if I want to.
Here’s our HTML:
<html>
<body>
<button>Hello</button>
<main>
<button>There</button>
</main>
<button>Friend</button>
</body>
</html>We’re going to set up some conditional state variables based on the main placement. (Yep, contrived example, but this is just for demonstration purposes.)
Here’s our CSS:
:root {
--if-main: ;
--if-not-main: initial;
}
main {
--if-main: initial;
--if-not-main: ;
}
button {
background:
var(--if-main, pink)
var(--if-not-main, blue);
color:
var(--if-main, blue)
var(--if-not-main, pink);
}By default, --if-main will be truthy (so no fallback) and --if-not-main will be falsy (so it’ll use the fallback).
When in <main>, we reverse that.
The button will style the background and foreground colors based on that state.
And here’s what we get:
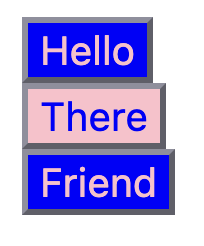
Beautiful.
You can play with that here:
Let’s Build Dark Mode
It’s 2025, so we want to support light and dark modes. There’s no end of articles on how to do this, and now you’re reading another one of them.
A common approach is to write different rules based on CSS classes.
body.-is-light {
background: orange;
color: green;
}
body.-is-dark {
background: darkorange;
color: darkgreen;
}That works if we’re manually controlling CSS classes on body, but these days we want to respect system settings, so we use media selectors like so:
@media (prefers-color-scheme: light) {
body {
background: orange;
color: green;
}
}
@media (prefers-color-scheme: dark) {
body {
background: darkorange;
color: darkgreen;
}
}But now we can’t give users a nice toggle on the page to control their light/dark modes, so we’ll want to bring the CSS classes back with the media selectors:
body.-is-light {
background: orange;
color: green;
}
body.-is-dark button {
background: darkorange;
color: darkgreen;
}
@media (prefers-color-scheme: light) {
body {
background: orange;
color: green;
}
}
@media (prefers-color-scheme: dark) {
body {
background: darkorange;
color: darkgreen;
}
}Okay, now things are just out of control. And we haven’t moved beyond the <body> tag. We’d have to repeat this for everything else we want to style!
Yuck. I hate CSS.
Let’s Hate CSS Less
It all comes down to this. We’re going to take our building blocks and clean this all up.
Here’s our plan of attack:
- We’re going to define some truthy and falsy CSS variables saying if we’re in light or dark mode.
- We’re going to consolidate the styles for our components and use our conditional
var()statements.
We’ll first set up our state variables. We only need to do this once for the whole codebase.
/* We'll make light mode our default. Everyone loves light mode. */
:root,
:root.-is-light {
--if-light: initial;
--if-dark: ;
color-scheme: light;
}
:root.-is-dark {
--if-light: ;
--if-dark: initial;
color-scheme: dark light;
}
@media (prefers-color-scheme: light) {
:root {
--if-light: initial;
--if-dark: ;
color-scheme: light;
}
}
@media (prefers-color-scheme: dark) {
:root {
--if-light: ;
--if-dark: initial;
color-scheme: dark light;
}
}Now let’s use all that to style <body> and <button>:
body {
background:
var(--if-light, orange)
var(--if-dark, darkorange);
color:
var(--if-light, darkgreen)
var(--if-dark, blue);
}
button {
background:
var(--if-light, pink)
var(--if-dark, blue);
color:
var(--if-light, blue)
var(--if-dark, pink);
}Look at that. So much simpler to maintain. And we can extend that too, if we want to add high-constrast mode or something.
Let’s test it.
Here it is when we switch our system to dark mode:

Far less eye strain than light. I’m sold.
Now light mode:

And system dark mode with <html class="is-light"> overriding to light mode.
And system light mode with <html class="is-dark"> overriding to dark mode.
Perfection.
You can play with that one here:
Nesting Conditionals!
That’s right, you can nest them! Let’s update our Light/Dark Mode example to make a prettier color scheme, because I’m starting to realize what we had was kind of ugly.
We’ll define new --if-pretty and --if-ugly states to go along with --if-dark and --if-light:
:root,
:root.-is-light {
--if-pretty: ;
--if-ugly: initial;
...
}
:root.-is-pretty {
--if-pretty: initial;
--if-ugly: ;
}
...And now we can build some truly beautiful styling, using nested conditionals:
body {
background:
var(--if-pretty,
var(--if-light,
linear-gradient(
in hsl longer hue 45deg,
red 0 100%)
)
)
var(--if-dark,
black
linear-gradient(
in hsl longer hue 45deg,
rgba(255, 0, 0, 20%) 0 100%)
)
)
)
var(--if-ugly,
var(--if-light, orange)
var(--if-dark, darkorange)
);
color:
var(--if-pretty,
var(--if-light, black)
var(--if-dark, white)
)
var(--if-ugly,
var(--if-light, darkgreen)
var(--if-dark, blue)
);
font-size: 100%;
}
button {
background:
var(--if-pretty,
radial-gradient(
ellipse at top,
orange,
transparent
),
radial-gradient(
ellipse at bottom,
orange,
transparent
)
)
var(--if-ugly,
var(--if-light, pink)
var(--if-dark, blue)
);
color:
var(--if-pretty, black)
var(--if-ugly,
var(--if-light, blue)
var(--if-dark, pink)
);
}In standard Ugly Mode, this looks the same as before, but when we apply Pretty Mode with Light Mode, we get:

And then with Dark Mode:

I am available for design consulting work on a first-come, first-serve basis only.
Here it is so you can enjoy it yourself:
A Backport from If()
Google’s article on if() has a neat demo showing how you can style some cards based on the value of a data-status= attribute. Based on whether the value is pending, complete, or anything else, the cards will be placed in different columns and have different background and border colors.
Here’s the card:
<div class="card" data-status="complete">
...
</div>Here’s how you’d do that with if() (from their demo):
.card {
--status: attr(data-status type(<custom-ident>));
border-color: if(
style(--status: pending): royalblue;
style(--status: complete): seagreen;
else: gray);
background-color: if(
style(--status: pending): #eff7fa;
style(--status: complete): #f6fff6;
else: #f7f7f7);
grid-column: if(
style(--status: pending): 1;
style(--status: complete): 2;
else: 3);
}To do this with CSS Variables, we can define our states using CSS selectors on the attribute, and then style it the way we did earlier:
/* Define our variables and conditions. */
.card {
--if-pending: ;
--if-complete: ;
--if-default: initial;
}
.card[data-status="pending"] {
--if-pending: initial;
--if-default: ;
}
.card[data-status="complete"] {
--if-complete: initial;
--if-default: ;
}
/* Style our cards. */
.card {
border-color:
var(--if-pending, royalblue)
var(--if-complete, seagreen)
var(--if-default, grey);
background-color:
var(--if-pending, #eff7fa)
var(--if-complete, #f6fff6)
var(--if-default, #f7f7f7);
grid-column:
var(--if-pending, 1)
var(--if-complete, 2)
var(--if-default, 3);
}Here’s the ported version, live:
It’s Available Now!
You can use this today in all browsers that support CSS Variables. That’s.. counts.. years worth of browsers.
It requires a bit more work to set up the variables, but the nice thing is, once you’ve done that, the rest is highly maintainable. And usage is close enough to that of if() that you can more easily transition once support is widespread.
We’ve based Ink, our (still very young) CSS component library we use for Review Board, around this conditionals pattern. It’s helped us to support light and dark modes along with the beginnings of low- and high-contrast modes and state for some components without tearing our hair out.
Give it a try, play with the demos, and see if it’s a good fit for your codebase. Begin taking advantage of what if() has to offer today, so you can more easily port tomorrow.
What If()? Using Conditional CSS Variables Read More »