Python offers a handy module called pprint, which has helpers for formatting and printing data in a nicely-formatted way. If you haven’t used this, you should definitely explore it!
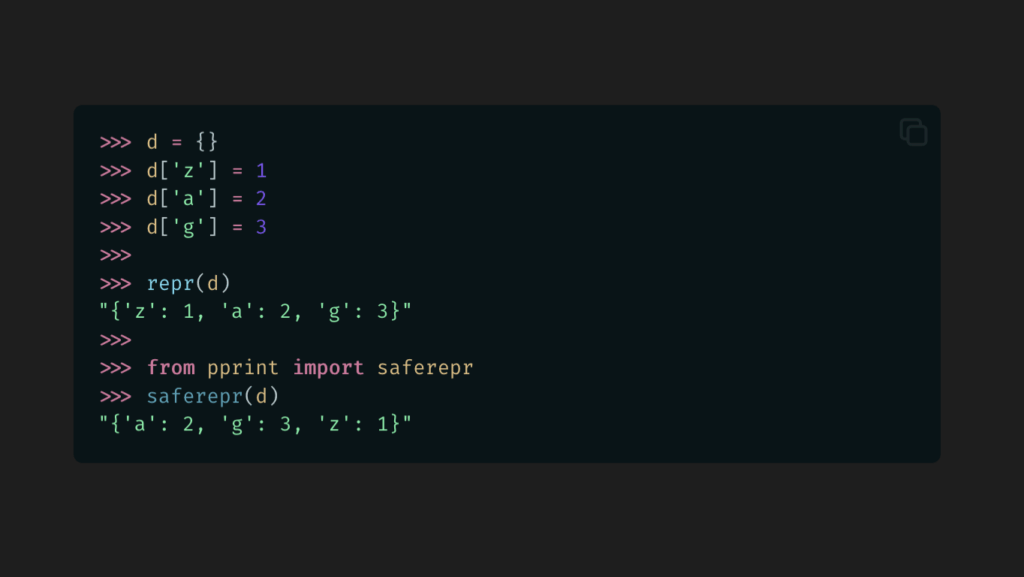
Most people will reach for this module when using pprint.pprint() (aka pprint.pp()) or pprint.pformat(), but one under-appreciated method is pprint.saferepr(), which advertises itself as returning a string representation of an object that is safe from some recursion issues. They demonstrate this as:
>>>import pprint>>> stuff =['spam','eggs','lumberjack','knights','ni']>>> stuff.insert(0, stuff)>>> pprint.saferepr(stuff)"[<Recursion on list with id=4370731904>, 'spam', 'eggs', 'lumberjack', 'knights', 'ni']"
But actually repr() handles this specific case just fine:
Pretty minimal difference there. Is there another reason we might care about saferepr()?
Dictionary string comparisons!
saferepr() first sets up the pprint pretty-printing machinery, meaning it takes care of things like sorting keys in dictionaries.
This is great! This is really handy when writing unit tests that need to compare, say, logging of data.
See, modern versions of CPython 3 will preserve insertion order of keys into dictionaries, which can be nice but aren’t always great for comparison purposes. If you’re writing a unit test, you probably want to feel confident about the string you’re comparing against.
Let’s take a look at repr() vs. saferepr() with a basic dictionary.
A nice, stable order. Now we don’t have to worry about a unit test breaking on different versions or implementations or with different logic.
saferepr() will disable some of pprint()`’s typical output limitations. There’s no max dictionary depth. There’s no max line width. You just get a nice, normalized string of data for comparison purposes.
But not for sets…
Okay, it’s not perfect. Sets will still use their standard representation (which seems to be iteration order), and this might be surprising given how dictionaries are handled.
Interestingly, pprint() and pformat()will sort keys if it needs to break them across multiple lines, but otherwise, nope.
I’ve been doing some work on Review Board and our utility library Typelets, and thought I’d share some of the intricacies of function signatures and their typing in Python.
We have some pretty neat Python typing utilities in the works to help a function inherit another function’s types in their own *args and **kwargs without rewriting a TypedDict. Useful for functions that need to forward arguments to another function. I’ll talk more about that later, but understanding how it works first requires understanding a bit about how Python sees functions.
Function signatures
Python’s inspect module is full of goodies for analyzing objects and code, and today we’ll explore the inspect.signature() function.
inspect.signature() is used to introspect the signature of another function, showing its parameters, default values, type annotations, and more. It can also aid IDEs in understanding a function signature. If a function has __signature__ defined, it will reference this (at least in CPython), and this gives highly-dynamic code the ability to patch signatures at runtime. (If you’re curious, here’s exactly how it works).
There are a few places where knowing the signature can be useful, such as:
Automatically-crafting documentation (Sphinx does this)
Checking if a callback handler accepts the right arguments
Checking if an implementation of an interface is using deprecated function signatures
Let’s set up a function and take a look at its signature.
If you guessed it wouldn’t have cls, you’d be right.
Only unbound methods (definitions of methods on a class) will have a self parameter in the signature. Bound methods (callable methods bound to an instance of a class) and classmethods (callable methods bound to a class) don’t. And this makes sense, if you think about it, because this signature represents what the call accepts, not what the code defining the method looks like.
You don’t pass a self when calling a method on an object, or a cls when calling a classmethod, so it doesn’t appear in the function signature. But did you know that you can call an unbound method if you provide an object as the self parameter? Watch this:
In this case, the unbound method MyClass.my_method has a self argument in its signature, meaning it takes it in a call. So, we can just pass in an instance. There aren’t a lot of cases where you’d want to go this route, but it’s helpful to know how this works.
What are bound and unbound methods?
I briefly touched upon this, but:
Unbound methods are just functions. Functions that are defined on a class.
Bound methods are a function where the very first argument (self or cls) is bound to a value.
>>>defmy_func(self):...print('I am',self)...>>>classMyClass:.........>>> obj =MyClass()>>> method = my_func.__get__(MyClass)>>> method<bound method my_func of <__main__.MyClass object at 0x100ea20d0>>>>> method.__self__<__main__.MyClass object at 0x100ea20d0>>>> inspect.ismethod(method)True>>>method()I am <__main__.MyClass object at 0x100ea20d0>
my_func wasn’t even defined on a class, and yet we could still make it a bound method tied to an instance of MyClass.
You can think of a bound method as a convenience over having to pass in an object as the first parameter every time you want to call the function. As we saw above, we can do exactly that, if we pass it to the unbound method, but binding saves us from doing this every time.
You’ll probably never need to do this trick yourself, but it’s helpful to know how it all ties together.
By the way, @staticmethod is a way of telling Python to never make an unbound method into a bound method when instantiating the object (it stays a function), and @classmethod is a way of telling Python to bind it immediately to the class it’s defined on (and not rebind when instantiating an object from the class).
How do you tell them apart?
If you have a function, and you don’t know if it’s a standard function, a classmethod, a bound method, or an unbound method, how can you tell?
Bound methods have a __self__ attribute pointing to the parent object (and inspect.ismethod() will be True).
Classmethods have a __self__ attribute pointing to the parent class (and inspect.ismethod() will be True).
They might have a self or cls parameter in the signature, but they might not have those names (and other functions may define them).
They should have a . in its __qualname__ attribute. This is a full .-based path to the method, relative to the module.
Splitting __qualname__, the last component would be the name. The previous component won’t be <locals> (but if <locals> is found, you’re going to have trouble getting to the method).
If the full path is resolvable, the parent component should be a class (but it might not be).
You could… resolve the parent module to a file and walk its AST and find the class and method based on __qualname__. But this is expensive and probably a bad idea for most cases.
Standard functions are the fallback.
Since unbound methods are standard functions that are just defined on a class, it’s difficult to really tell the difference. You’d have to rely on heuristics and know you won’t always get a definitive answer.
(Interesting note: In Python 2, unbound methods were special kinds of functions with a __self__ that pointed to the class they were defined on, so you could easily tell!)
This is very simplistic, and can’t be used to represent positional-only arguments, keyword-only arguments, default arguments, *args, or **kwargs. For that, you can define a Protocol with __call__:
from typing import ProtocolclassMyCallback(Protocol):def__call__(self,# This won't be part of the function signaturea:int,b:str,/,c: dict[str,str]|None,*,d:bool=False,**kwargs,)->str:...
Type checkers will then treat this as a Callable, effectively. If we take my_func from the top of this post, we can assign to it:
cb: MyCallback = my_func # This works
What if we want to assign a method from a class? Let’s try bound and unbound.
classMyClass:defmy_func(self,a:int,b:str,/,c: dict[str,str]|None,*,d:bool=False,**kwargs,)->str:return'42'cb2: MyCallback = MyClass.my_func # This failscb3: MyCallback =MyClass().my_func # This works
What happened? It’s that self again. Remember, the unbound method has self in the signature, and the bound method does not.
Let’s add self and try again.
classMyCallback(Protocol):def__call__(_proto_self,# This won't be part of the function signatureself: Any,a:int,b:str,/,c: dict[str,str]|None,*,d:bool=False,**kwargs,)->str:...cb2: MyCallback = MyClass.my_func # This workscb3: MyCallback =MyClass().my_func # This fails
What happened this time?! Well, now we’ve matched the unbound signature with self, but not the bound signature without it.
Solving this gets… verbose. We can create two versions of this: Unbound, and Bound (or plain function, or classmethod):
classMyUnboundCallback(Protocol):def__call__(_proto_self,# This won't be part of the function signatureself: Any,a:int,b:str,/,c: dict[str,str]|None,*,d:bool=False,**kwargs,)->str:...classMyCallback(Protocol):def__call__(_proto_self,# This won't be part of the function signaturea:int,b:str,/,c: dict[str,str]|None,*,d:bool=False,**kwargs,)->str:...# These workcb4: MyCallback = my_funccb5: MyCallback =MyClass().my_func# These fail correctlycb7: MyUnboundCallback = my_funccb8: MyUnboundCallback =MyClass().my_funccb9: MyCallback = MyClass.my_func
This means we can use union types (MyUnboundCallback | MyCallback) to cover our bases.
It’s not flawless. Depending on how you’ve typed your signature, and the signature of the function you’re setting, you might not get the behavior you want or expect. As an example, any method with a leading self-like parameter (basically any parameter coming before your defined signature) will type as MyUnboundCallback, because it might be! Remember, we can turn any function into a bound method for an arbitrary class using __get__. That may or may not matter, depending on what you need to do.
What do I mean by that?
defmy_bindable_func(x,a:int,b:str,/,c: dict[str,str]|None,*,d:bool=False,**kwargs,)->str:return''x1: MyCallback = my_bindable_func # This failsx2: MyUnboundCallback = my_bindable_func # This works
x may not be named self, but it’ll get treated as one, because if we do my_bindable_func.__get__(some_obj), then some_obj will be bound to x and callers won’t have to pass anything to x.
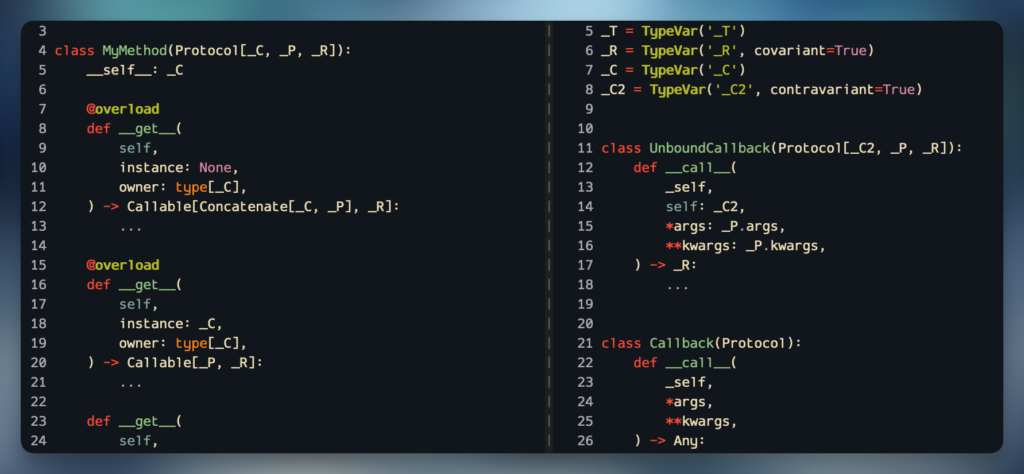
Okay, what if you want to return a function that can behave as an unbound method (with self) that can become an unbound method (with __get__)? We can mostly do it with:
And those are type-compatible with the MyCallback and MyUnboundCallback we built earlier, since the signatures match:
# These workcb10: MyUnboundCallback = MyClass.my_methodcb11: MyCallback =MyClass().my_method# These fail correctlycb12: MyUnboundCallback =MyClass().my_methodcb13: MyCallback = MyClass.my_method
And if we wanted, we could modify that ParamSpec going into the MyMethod from make_method() and that’ll impact what the type checkers expect during the call.
Hopefully you can see how this can get complex fast, and involve some tradeoffs.
I personally believe Python needs a lot more love in this area. Types for the different kinds of functions/methods, better specialization for Callable, and some of the useful capabilities from TypeScript would be nice (such as Parameters<T>, ReturnType<T>, OmitThisParameter<T>, etc.). But this is what we have to work with today.
My teachers said to always write a conclusion
What have we learned?
Python’s method signatures are different when bound vs. unbound, and this can affect typing.
Unbound methods aren’t really their own thing, and this can lead to some challenges.
Any method can be a bound method with a call to __get__().
Callable only gets you so far. If you want to type complex functions, write a Protocol with a __call__() signature.
If you want to simulate a bound/unbound-aware type, you’ll need Protocol with __get__().
I feel like I just barely scratched the surface here. There’s a lot more to functions, working with signatures, and challenges around typing than I covered here. We haven’t talked about how you can rewrite signatures on the fly, how annotations are represented, what functions look under the hood, or how bytecode behind functions are mutable at runtime.
I’ll leave some of that for future posts. And I’ll have more to talk about when we expand Typelets with the new parameter inheritance capabilities. It builds upon a lot of what I covered today to perform some very neat and practical tricks for library authors and larger codebases.
What do you think? Did you learn something? Did I get something wrong? Have you done anything interesting or unexpected with signatures or typing around functions you’d like to share? I want to hear about it!
Python dataclasses are a really nice feature for constructing classes that primarily hold or work with data. They can be a good alternative to using dictionaries, since they allow you to add methods, dynamic properties, and subclasses. They can also be a good alternative to building your own class by hand, since they don’t need a custom __init__() that reassigns attributes and provide methods like __eq__() out of the box.
One small tip to keeping dataclasses maintainable is to always construct them with kw_only=True, like so:
from dataclasses import dataclass
@dataclass(kw_only=True)
class MyDataClass:
x: int
y: str
z: bool = True
This will construct an __init__() that looks like this:
class MyDataClass:
def __init__(
self,
*,
x: int,
y: str,
z: bool = True,
) -> None:
self.x = x
self.y = y
self.z = z
Instead of:
class MyDataClass:
def __init__(
self,
x: int,
y: str,
z: bool = True,
) -> None:
self.x = x
self.y = y
self.z = z
That * in the argument list means everything that follows must be passed as a keyword argument, instead of a positional argument.
There are two reasons you probably want to do this:
It allows you to reorder the fields on the dataclass without breaking callers. Positional arguments means a caller can use MyDataClass(1, 'foo', False), and if you remove/reorder any of these arguments, you’ll break those callers unexpectedly. By forcing callers to use MyDataClass(x=1, y='foo', z=False), you remove this risk.
It allows subclasses to add required fields. Normally, any field with a default value (like z above) will force any fields following it to also have a default. And that includes all fields defined by subclasses. Using kw_only=True gives subclasses the flexibility to decide for themselves which fields must be provided by the caller and which have a default.
These reasons are more important for library authors than anything. We spend a lot of time trying to ensure backwards-compatibility and forwards-extensibility in Review Board, so this is an important topic for us. And if you’re developing something reusable with dataclasses, it might be for you, too.
Update: One important point I left out is Python compatibility. This flag was introduced in Python 3.10, so if you’re supporting older versions, you won’t be able to use this just yet. If you want to optimistically enable this just on 3.10+, one approach would be:
import sys
from dataclasses import dataclass
if sys.version_info[:2] >= (3, 10):
dataclass_kwargs = {
'kw_only': True,
}
else:
dataclass_kwargs = {}
...
@dataclass(**dataclass_kwargs)
class MyDataClass:
...
...
But this won’t solve the subclassing issue, so you’d still need to ensure any subclasses use default arguments if you want to support versions prior to 3.10.
AI has been all the rage lately, with solutions like Stable Diffusion for image generation, GPT-3 for text generation, and CoPilot for code development becoming publicly available to the masses.
That excitement ramped up this week with the release of ChatGPT, an extremely impressive chat-based AI system leveraging the best GPT has to offer.
I decided last night to take ChatGPT for a spin, to test its code-generation capabilities. And I was astonished by the experience.
Together, we built a simulation of bugs foraging for food in a 100×100 grid world, tracking essentials like hunger and life, reproducing, and dealing with hardships involving seasonal changes, natural disasters, and predators. All graphically represented.
We’re going to explore this in detail, but I want to start off by showing you what we built:
One of my (many) tasks lately has been to rework unit and integration tests for Review Bot, our automated code review add-on for Review Board.
The challenge was providing a test suite that could test against real-world tools, but not require them. An ever-increasing list of compatible tools has threatened to become an ever-increasing burden on contributors. We wanted to solve that.
So here’s how we’re doing it.
First off, unit test tooling
First off, this is all Python code, which you can find on the Review Bot repository on GitHub.
We make heavy use of kgb, a package we’ve written to add function spies to Python unit tests. This goes far beyond Mock, allowing nearly any function to be spied on without having to be replaced. This module is a key component to our solution, given our codebase and our needs, but it’s an implementation detail — it isn’t a requirement for the overall approach.
Still, if you’re writing complex Python test suites, check out kgb.
Deciding on the test strategy
Review Bot can talk to many command line tools, which are used to perform checks and audits on code. Some are harder than others to install, or at least annoying to install.
We decided there’s two types of tests we need:
Integration tests — ran against real command line tools
Simulation tests — ran against simulated output/results that would normally come from a command line tool
Being that our goal is to ease contribution, we have to keep in mind that we can’t err too far on that side at the expense of a reliable test suite.
We decided to make these the same tests.
The strategy, therefore, would be this:
Each test would contain common logic for integration and simulation tests. A test would set up state, perform the tool run, and then check results.
Integration tests would build upon this by checking dependencies and applying configuration before the test run.
Simulation tests would be passed fake output or setup data needed to simulate that tool.
This would be done without any code duplication between integration or simulation tests. There would be only one test function per expectation (e.g., a successful result or the handling of an error). We don’t want to worry about tests getting out of sync.
Regression in our code? Both types of tests should catch it.
Regression or change in behavior in an integrated tool? Any fixes we apply would update or build upon the simulation.
Regression in the simulation? Something went wrong, and we caught it early without having to run the integration test.
Making this all happen
We introduced three core testing components:
@integration_test() — a decorator that defines and provides dependencies and input for an integration test
@simulation_test() — a decorator that defines and provides output and results for a simulation test
Any test class that needs to run integration and simulation tests will use ToolTestCaseMetaClass and then apply either or both @integration_test/@simulation_test decorators to the necessary test functions.
When a decorator is applied, the test function is opted into that type of test. Data can be passed into the decorator, which is then passed into the parent test class’s setup_integration_test() or setup_simulation_test().
These can do whatever they need to set up that particular type of test. For example:
Integration test setup defaults to checking dependencies, skipping a test if not met.
Simulation test setup may write some files or spy on a subprocess.Popen() call to fake output.
For example:
class MyTests(kgb.SpyAgency, TestCase,
metaclass=ToolTestCaseMetaClass):
def setup_simulation_test(self, output):
self.spy_on(execute, op=kgb.SpyOpReturn(output))
def setup_integration_test(self, exe_deps):
if not are_deps_found(exe_deps):
raise SkipTest('Missing one or more dependencies')
@integration_test(exe_deps=['mytool'])
@simulation_test(output=(
b'MyTool 1.2.3\n'
b'Scanning code...\n'
b'0 errors, 0 warnings, 1 file(s) checked\n'
))
def test_execute(self):
"""Testing MyTool.execute"""
...
When applied, ToolTestCaseMetaClass will loop through each of the test_*() functions with these decorators applied and split them up:
Test functions with @integration_test will be split out into a test_integration_<name>() function, with a [integration test] suffix appended to the docstring.
Test functions with @simulation_test will be split out into test_simulation_<name>(), with a [simulation test] suffix appended.
The above code ends up being equivalent to:
class MyTests(kgb.SpyAgency, TestCase):
def setup_simulation_test(self, output):
self.spy_on(execute, op=kgb.SpyOpReturn(output))
def setup_integration_test(self, exe_deps):
if not are_deps_found(exe_deps):
raise SkipTest('Missing one or more dependencies')
def test_integration_execute(self):
"""Testing MyTool.execute [integration test]"""
self.setup_integration_test(exe_deps=['mytool'])
self._test_common_execute()
def test_simulation_execute(self):
"""Testing MyTool.execute [simulation test]"""
self.setup_simulation_test(output=(
b'MyTool 1.2.3\n'
b'Scanning code...\n'
b'0 errors, 0 warnings, 1 file(s) checked\n'
))
self._test_common_execute()
def _test_common_execute(self):
...
Pretty similar, but less to maintain in the end, especially as tests pile up.
And when we run it, we get something like:
Testing MyTool.execute [integration test] ... ok
Testing MyTool.execute [simulation test] ... ok
...
Or, you know, with a horrible, messy error.
Iterating on tests
It’s become really easy to maintain and run these tests.
We can now start by writing the integration test, modify the code to log any data that might be produced by the command line tool, and then fake-fail the test to see that output.
Once it’s running correctly in both tests, our job is done.
From then on, anyone working on this code can just simply run the test suite and make sure their change hasn’t broken any simulation tests. If it has, and it wasn’t intentional, they’ll have a great starting point in diagnosing their issue, without having to install anything.
Anything that passes simulation tests can be considered a valid contribution. We can then test against the real tools ourselves before landing a change.
Development is made simpler, and there’s no worry about regressions.
Going forward
We’re planning to apply this same approach to both Review Board and RBTools. Both currently require contributors to install a handful of command line tools or optional Python modules to make sure they haven’t broken anything, and that’s a bottleneck.
In the future, we’re looking at making use of python-nose‘s attrib plugin, tagging integration and simulation tests and making it trivially easy to run just the suites you want.
We’re also considering pulling out the metaclass and decorators into a small, reusable Python packaging, making it easy for others to make use of this pattern.
Every so often you hit a bug that makes you question your sanity. The past several days have been spent chasing one of the more confusing ones I’ve seen in a long time.
Review Board 1.7 added the ability to set the server-wide timezone. During development, we found problems using SSH with a non-default timezone. This only happened when updating os.environ[‘TZ’] to something other than our default of UTC. We’d see the SSH process (rbssh, our wrapper for SSH communication) break due to an EOF on stdin and stdout, and then we’d see the development server reload itself.
Odd.
Since this originated with a Subversion repository, I first suspected libsvn. I spent some time going through their code to see if a timezone update would break something. Perhaps timeout logic. That didn’t turn up anything interesting, but I couldn’t rule it out.
Other candidates for suspicion were rbssh itself, paramiko (the SSH library), Django, and the trickster god Loki. We just had too many moving pieces to know for sure.
So I wrote a little script to get in-between a calling process and another process and log all communication between them. I tested this with rbssh and with plain ol’ ssh. rbssh was the only one that broke. Strange, since it wasn’t doing anything obviously wrong, and it worked with the default timezone. Unless it was Paramiko somehow…
For the heck of it, I tried copying some of rbssh’s imports into this new script. Ah-ha! It dropped its streams when importing Paramiko, same as rbssh. Interesting. Time to dig into that code.
The base paramiko module imports a couple dozen other modules, so I started by narrowing it down and reducing imports until I found the common one that breaks things. Well that turned out to be a module that imported Crypto.Random. Replacing the paramiko import in my wrapper with Crypto.Random verified that that was the culprit.
Getting closer…
I rinsed and repeated with Crypto.Random, digging through the code and seeing what could have broken. Hmm, that code’s pretty straight-forward, but there are some native libraries in there. Well, all this is in a .egg file (not an extracted .egg directory), making it hard to look through, so I extracted it and replaced it with a .egg directory.
Woah! The problem went away!
I glance at the clock. 3AM. I’m not sure I can trust what I’m seeing anymore. Crypto.Random breaks rbssh, but only when installed as a .egg file and not a .egg directory. That made no sense, but I figured I’d deal with it in the morning.
My dreams that night were filled with people wearing “stdin” and “stdout” labels on their foreheads, not at all getting along.
Today, I considered just ripping out timezone support. I didn’t know what else to do. Though, since I’m apparently a bit of a masochist, I decided to look into this just a little bit more. And finally struck gold.
With my Django development server running, I opened up a separate, plain Python shell. In it, I typed “import Crypto.Random”. And suddenly saw my development server reload.
How could that happen, I wondered. I tried it again. Same result. And then… lightbulb!
Django reloads the dev server when modules change. Crypto is a self-contained .egg file with native files that must be extracted and added to the module path. Causing Django to reload. Causing it to drop the spawned rbssh process. Causing the streams to disconnect. Ah-ha. This had to be it.
One last piece of the puzzle. The timezone change.
I quickly located their autoreload code and pulled it up. Yep, it’s comparing modified timestamps. We have two processes with two different ideas of what the current timezone is (one UTC, one US/Pacific, in my case), meaning when rbssh launched and imported Crypto, we’d get a bunch of files extracted with US/Pacific-based timestamps and not UTC, triggering the autoreload.
Now that the world makes sense again, I can finally fix the problem!
All told, that was about 4 or 5 days of debugging. Certainly not the longest debugging session I’ve had, but easily one of the more confusing ones in a while. Yet in the end, it’s almost obvious.